
教師あり学習
東京都のCOVID-19モニタリングデータ(1)
画像の識別など、数か月程度で考えれば時系列を気にしなくて済むデータと比べて、時系列データは考慮すべきことが多い。 ここでは、その1つの例として、東京都の新型コロナウイルス感染症対策サイト からデータを取得し、少しばかり、実際の作業をやってみようと思う。
検証誤差と汎化誤差
機械学習では、train-valid-test分割 1 という方法が良く用いられる。 例えば、https://towardsdatascience.com/how-to-split-data-into-three-sets-train-validation-and-test-and...
不均衡なデータ
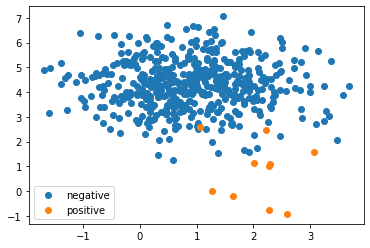
Bioinformaticsの分野をやっていると、不均衡なデータによく出くわすものである。 特に、正例 positive が少なく、負例 negative が多いケースが多い。 このような状態だと、何も考えずに構築したモデルは、いかなるデータが来ようとも負例として予測してしまうことすらある。
内挿と外挿
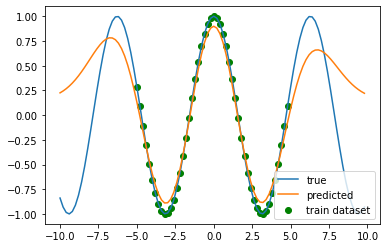
機械学習モデルを構築する上で、 本来データが存在するはずなのにサンプリングできていない(データを取得できていない)空間があると、 その部分の予測精度は落ちてしまう。これについて少し触れてみたい。
予測誤差
検証誤差と汎化誤差
機械学習では、train-valid-test分割 1 という方法が良く用いられる。 例えば、https://towardsdatascience.com/how-to-split-data-into-three-sets-train-validation-and-test-and...
内挿と外挿
機械学習モデルを構築する上で、 本来データが存在するはずなのにサンプリングできていない(データを取得できていない)空間があると、 その部分の予測精度は落ちてしまう。これについて少し触れてみたい。
因子分析
因子分析と主成分分析
因子分析と主成分分析は似通った手法のように見える。 しかし、実際には大きく異なる点がある。
主成分分析
因子分析と主成分分析
因子分析と主成分分析は似通った手法のように見える。 しかし、実際には大きく異なる点がある。
教師なし学習
因子分析と主成分分析
因子分析と主成分分析は似通った手法のように見える。 しかし、実際には大きく異なる点がある。
共溶媒分子動力学法
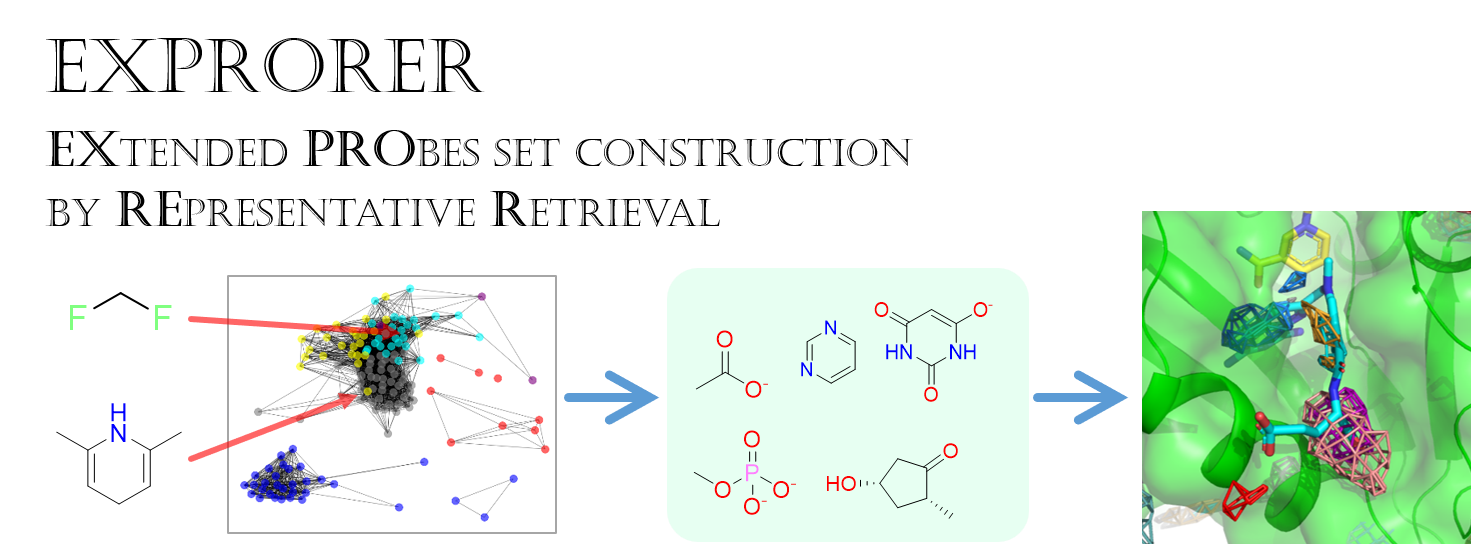
共溶媒分子動力学 (MSMD) 法における共溶媒セットの構築手法 EXPRORER
2021年6月に Journal of Chemical Information and Modeling 誌に掲載された、 EXPRORER (EXtended PRObes set construction by REpresentative Retrieval) の話。
分子動力学法
共溶媒分子動力学 (MSMD) 法における共溶媒セットの構築手法 EXPRORER
2021年6月に Journal of Chemical Information and Modeling 誌に掲載された、 EXPRORER (EXtended PRObes set construction by REpresentative Retrieval) の話。
EXPRORER
共溶媒分子動力学 (MSMD) 法における共溶媒セットの構築手法 EXPRORER
2021年6月に Journal of Chemical Information and Modeling 誌に掲載された、 EXPRORER (EXtended PRObes set construction by REpresentative Retrieval) の話。
データセット
不均衡なデータ
Bioinformaticsの分野をやっていると、不均衡なデータによく出くわすものである。 特に、正例 positive が少なく、負例 negative が多いケースが多い。 このような状態だと、何も考えずに構築したモデルは、いかなるデータが来ようとも負例として予測してしまうことすらある。
読み物
ブログを書き始めた理由
ふとした思いつきで、ブログを書けるようにした (そのためにホームページの見た目を全面更新することになったのだが)。
時系列データ
東京都のCOVID-19モニタリングデータ(1)
画像の識別など、数か月程度で考えれば時系列を気にしなくて済むデータと比べて、時系列データは考慮すべきことが多い。 ここでは、その1つの例として、東京都の新型コロナウイルス感染症対策サイト からデータを取得し、少しばかり、実際の作業をやってみようと思う。