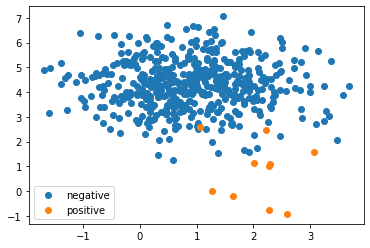
東京都のCOVID-19モニタリングデータ(1)
画像の識別など、数か月程度で考えれば時系列を気にしなくて済むデータと比べて、時系列データは考慮すべきことが多い。 ここでは、その1つの例として、東京都の新型コロナウイルス感染症対策サイト からデータを取得し、少しばかり、実際の作業をやってみようと思う。
何をするか決める
まず、ここで何をやるかを決めておこう。 今回は、 東京都の翌日の新規陽性者数を予測する ことをやってみる1。
データを取得する
ホームページにアクセスすると、さまざまなモニタリング項目が表示され、 その左下に小さく オープンデータを入手 というリンクが存在している。 ここでは、 モニタリング項目(1) 新規陽性者数 を対象に作業を行なう。 当該のリンクをクリックすると、このページに遷移する。
ここから 130001_tokyo_covid19_patients.csv 取得する。
このデータの中身をpandasで見てみよう。(Excelで開くにはサイズが大きすぎる、何故かはすぐにわかる)
import pandas as pd
df = pd.read_csv("130001_tokyo_covid19_patients.csv", index_col="No")
print(df.head(5)) # Jupyterでは df.head(5) の方が綺麗に描画される
print(len(df)) # => 962,673

このデータを見ると、日々の件数ではなく、それぞれの陽性者の情報が記載されていることがわかる。 2022年2月25日現在、東京都の陽性者数の累計は95万人を超えているので、 おのずからこのcsvファイルも95万行以上のデータを持っている。
今回は新規陽性者数を予測したいだけなので、 個々の人間の情報は含まずに、公表_年月日 ごとに、 何人の新規陽性者がでたのかをまとめる。
print(df.describe()) # => 全国地方公共団体コード が len(df) と同じcountになっている = NaNが存在しない
new_patients = df.groupby("公表_年月日").count().reset_index()
new_patients["新規陽性者数"] = new_patients["全国地方公共団体コード"]
new_patients = new_patients[["公表_年月日", "新規陽性者数"]]
new_patients.to_csv("new_patients_tokyo.csv", index=None)
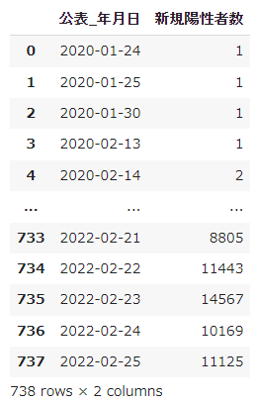
とりあえず、データは準備できた。 ここで作成したデータを添付しておく。
次回は、このデータの性質を考えて、どのような学習を組みたてるかを考えていこう。
-
本来は解析の目的があって、その目的に沿い、かつ予測が可能と思われる対象を決めるというステップを踏む必要がある。 ↩