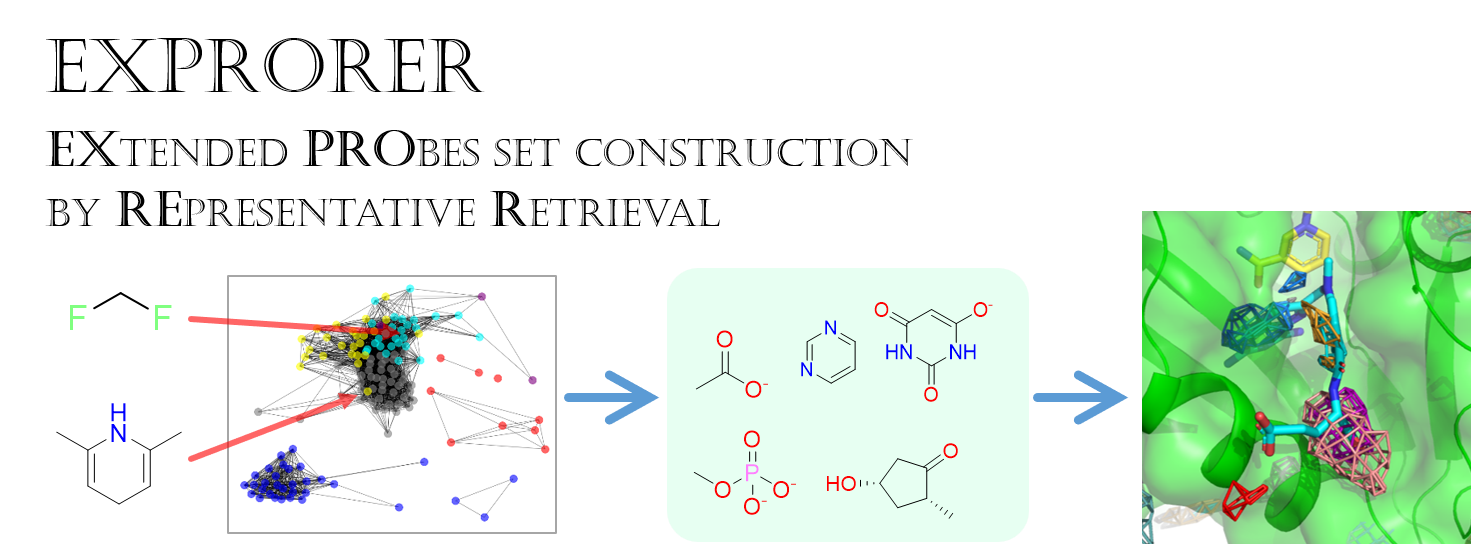
不均衡なデータ
Bioinformaticsの分野をやっていると、不均衡なデータによく出くわすものである。 特に、正例 positive が少なく、負例 negative が多いケースが多い。 このような状態だと、何も考えずに構築したモデルは、いかなるデータが来ようとも負例として予測してしまうことすらある。
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 不均衡データ(1対50)を作成
X, y = make_blobs(n_samples=[500,10], centers=None, random_state=0)
plt.scatter(*X[y==0].T, label="negative")
plt.scatter(*X[y==1].T, label="positive")
plt.legend()
plt.show()
from sklearn.svm import SVC
# 予測モデルの構築
# (説明のためにgammaを下げて問題を誘発している)
svc = SVC(gamma=0.01)
svc.fit(X, y)
svc.predict([[3,-1]])
これを行うと、[3, -1] は負例である、という予測結果が出てくる。
しかし、これを先ほど示した図に載せるとどこになるだろうか。
以下のようになり、明らかに正例であるべき場所である。
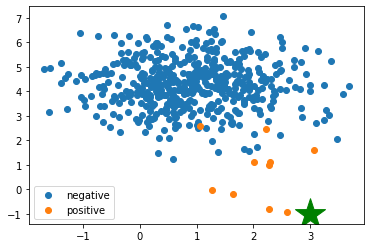
これは意図的に変数 \(\gamma\) を下げることで(モデルの複雑度を下げて)誘発しているが、単なる正解率に基づくハイパーパラメータ探索はいつのまにかこの問題に入りこんでしまう事がある。注意しなければならない。
関連参考文献(順不同)
- Alice Zheng, Amanda Casari 著、株式会社ホクソエム 訳『機械学習のための特徴量エンジニアリング』(オライリージャパン、2019年)
- 不均衡データに対して、ダウンサンプリングを行うことで不均衡を是正する方法を4.2.1節で説明している。
- 中山浩太郎 監修、塚本邦尊、山田典一、大澤文孝 著『東京大学のデータサイエンティスト育成講座』(マイナビ出版、2019年)
- 不均衡データに対する予測モデルの評価において、正解率を使うのではなくROC曲線のAUC (Area Under the Curve) を使うことを10-3-2-4節で述べている。
- 門脇大輔、阪田隆司、保坂桂佑、平松雄司 著『Kaggleで勝つデータ分析の技術』(技術評論社、2019年)
- 99.4%が負例であったKaggleのコンペについて2.6.5節で触れている。ここではROC曲線ではなくPR曲線のAUCを使う話をしている。